算法竞赛 STL 与库函数 风铃夜行 2025-07-05 2025-12-11 STL 与库函数 pb_ds 库 其中 gp_hash_table 使用的最多,其等价于 unordered_map ,内部是无序的。
1 2 3 #include <bits/extc++.h> #include <ext/pb_ds/assoc_container.hpp> template <class S , class T > using omap = __gnu_pbds::gp_hash_table<S, T, myhash>;
查找后继 lower_bound、upper_bound lower 表示 upper 表示 先进行排序 。
1 2 3 4 5 cout << lower_bound (a + start, a + end, x); cout << lower_bound (a, a + n, x) - a; upper_bound (a, a + n, k) - lower_bound (a, a + n, k)
数组打乱 shuffle 1 2 mt19937 rnd (chrono::steady_clock::now().time_since_epoch().count()) ;shuffle (ver.begin (), ver.end (), rnd);
二分搜索 binary_search 用于查找某一元素是否在容器中,相当于 find 函数。在使用前需要先进行排序 。
1 2 cout << binary_search (a + start, a + end, x);
批量递增赋值函数 iota 对容器递增初始化。
1 2 iota (a + start, a + end, x);
数组去重函数 unique 在使用前需要先进行排序 。
其作用是,对于区间 [开始位置, 结束位置) ,不停的把后面不重复的元素移到前面来 ,也可以说是用不重复的元素占领重复元素的位置 。并且返回去重后容器中不重复序列的最后一个元素的下一个元素 。所以在进行操作后,数组、容器的大小并没有发生改变 。
1 2 3 4 5 unique (a + start, a + end);a.erase (unique (ALL (a)), a.end ());
bit 库与位运算函数 __builtin_ 1 2 3 4 5 6 7 __builtin_popcount(x) __builtin_ffs(x) __builtin_ctz(x) bit_width (x)
注:以上函数的 ll 即可(例如 __builtin_popcountll(x) ), ull 。
数字转字符串函数 itoa 虽然能将整数转换成任意进制的字符串,但是其不是标准的C函数,且为Windows独有,且不支持 long long ,建议手写。
1 2 3 4 double val = 12.12 ;cout << to_string (val);
1 2 3 4 5 6 7 char ans[10 ] = {};itoa (12 , ans, 2 );cout << ans << endl;
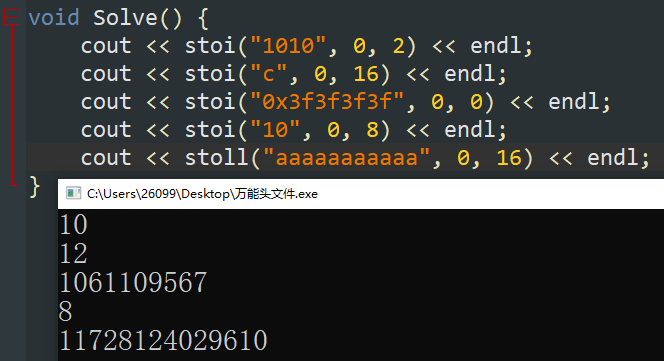
字符串转数字 1 2 3 4 5 6 7 8 9 10 cout << stoi ("12" ) << endl; cout << stoi ("1010" , 0 , 2 ) << endl; cout << stoi ("c" , 0 , 16 ) << endl; cout << stoi ("0x3f3f3f3f" , 0 , 0 ) << endl;
1 2 3 4 5 6 7 cout << atoi ("12" ) << endl; cout << atoi (" 12" ) << endl; cout << atoi ("-12abc" ) << endl; cout << atoi ("abc12" ) << endl;
全排列算法 next_permutation、prev_permutation 在提及这个函数时,我们先需要补充几点字典序相关的知识。
对于三个字符所组成的序列{a,b,c},其按照字典序的6种排列分别为:{abc},{acb},{bac},{bca},{cab},{cba}a (序列内最小元素),再对之后的元素排列。而 b < c ,所以 abc < acb 。同理,先固定 b (序列内次小元素),再对之后的元素排列。即可得出以上序列。
字典序顺序 输出的全排列;相对应的, 逆字典序顺序 输出的全排列。可以是数字,亦可以是其他类型元素。其直接在序列上进行更新,故直接输出序列即可。
1 2 3 4 5 6 7 8 9 10 11 int n;cin >> n; vector<int > a (n) ;for (auto &it : a) cin >> it;sort (a.begin (), a.end ());do { for (auto it : a) cout << it << " " ; cout << endl; } while (next_permutation (a.begin (), a.end ()));
字符串转换为数值函数 sto 可以快捷的将一串字符串 转换为指定进制的数字 。
使用方法
stoi(字符串, 0, x进制) :将一串
stoll(字符串, 0, x进制) :将一串 , ,
数值转换为字符串函数 to_string 允许将各种数值类型 转换为字符串类型。
1 2 string s = to_string (num);
判断非递减 is_sorted 1 2 cout << is_sorted (a + start, a + end);
累加 accumulate 1 2 cout << accumulate (a + start, a + end, x);
迭代器 iterator 1 2 3 4 5 UUU::iterator it; vector<int >::iterator it; vector<int >::reverse_iterator it;
其他函数 exp2(x) :返回
log2(x) :返回
gcd(x, y) / lcm(x, y) :以
容器与成员函数 元组 tuple 1 2 3 4 tuple<string, int , int > Student = {"Wida" , 23 , 45000 ); cout << get <0 >(Student) << endl;
数组 array 1 2 3 4 array<int , 3> x; [] cout << x[0 ];
变长数组 vector 1 2 3 4 5 6 7 8 9 10 resize (n) assign (n, 0 ) vector<int > ver[n + 1 ]; vector<vector<int >> ver (n + 1 ); vector dis (n + 1 , vector<int >(m + 1 )) ;vector dis (m + 1 , vector(n + 1 , vector<int >(n + 1 ))) ;
栈 stack 栈顶入,栈顶出。先进后出。
1 2 3 4 5 size () / empty ()push (x) top () pop ()
队列 queue 队尾进,队头出。先进先出。
1 2 3 4 5 size () / empty ()push (x) front () / back () pop ()
1 2 3 queue<int > q; q = queue <int >();
双向队列 deque 1 2 3 4 5 6 size () / empty () / clear ()push_front (x) / push_back (x)pop_front (x) / pop_back (x)front () / back ()begin () / end ()[]
优先队列 priority_queue 默认升序(大根堆),自定义排序需要重载 < 。
1 2 3 4 5 priority_queue<int , vector<int >, greater<int > > p; push (x); top (); pop ();
1 2 3 4 5 6 7 8 struct Node { int x; string s; friend bool operator < (const Node &a, const Node &b) { if (a.x != b.x) return a.x > b.x; return a.s > b.s; } };
字符串 string 1 size () / empty () / clear ()
1 2 3 4 5 6 cout << S.substr (1 , 12 ); find (x) / rfind (x);
有序、多重有序集合 set、multiset 默认升序(大根堆),
1 2 3 4 5 6 7 8 9 10 set<int , greater<> > s; size () / empty () / clear ()begin () / end ()++ / -- insert (x); find (x) / rfind (x); count (x); lower_cound (x); upper_cound (x);
特殊函数 next 和 prev 详解:
1 2 3 4 5 6 7 auto it = s.find (x); prev (it) / next (it); prev (it, 2 ) / next (it, 2 ); auto pre = prev (s.lower_bound (x)); int ed = *prev (S.end (), 1 );
erase(x); 有两种删除方式:
当x为某一元素时,删除所有 这个数,复杂度为
当x为迭代器时,删除这个迭代器。
1 2 3 4 5 6 7 8 9 10 11 12 13 set<int > S = {0 , 9 , 98 , 1087 , 894 , 34 , 756 }; auto it = S.begin ();int len = S.size ();for (int i = 0 ; i < len; ++ i) { if (*it >= 500 ) continue ; it = S.erase (it); }
map、multimap 默认升序(大根堆),
1 2 3 4 5 6 7 8 9 10 map<int , int , greater<> > mp; size () / empty () / clear ()begin () / end ()++ / -- insert ({x, y}); [] count (x); lower_cound (x); upper_cound (x);
erase(x); 有两种删除方式:
当x为某一元素时,删除所有以这个元素为下标的二元组 ,复杂度为
当x为迭代器时,删除这个迭代器。
慎用随机访问! ——当不确定某次查询是否存在于容器中时,不要直接使用下标查询,而是先使用 count() 或者 find() 方法检查key值,防止不必要的零值二元组被构造。
1 2 int q = 0 ;if (mp.count (i)) q = mp[i];
慎用自带的 pair、tuple 作为key值类型!使用自定义结构体!
1 2 3 4 5 6 7 8 struct fff { LL x, y; friend bool operator < (const fff &a, const fff &b) { if (a.x != b.x) return a.x < b.x; return a.y < b.y; } }; map<fff, int > mp;
bitset 将数据转换为二进制,从高位到低位排序,以
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 bitset<10> s; cin >> s; string S; cin >> S; bitset<32> B (S) ;int x; cin >> x;bitset<32> B1 (x) ;bitset<32> B2 = x; int x; cin >> x;bitset<x> ans; [] set (x) reset (x) flip (x) to_ullong () to_string () count () any () none () _Find_fisrt() _Find_next(x) bitset<23> B1 ("11101001" ) , B2 ("11101000" ) ;cout << (B1 ^ B2) << "\n" ; cout << (B1 | B2) << "\n" ; cout << (B1 & B2) << "\n" ; cout << (B1 == B2) << "\n" ; cout << B1 << " " << B2 << "\n" ;
哈希系列 unordered 通常指代 unordered_map、unordered_set、unordered_multimap、unordered_multiset,与原版相比不进行排序。
如果将不支持哈希的类型作为 key 值代入,编译器就无法正常运行,这时需要我们为其手写哈希函数。而我们写的这个哈希函数的正确性其实并不是特别重要(但是不可以没有),当发生冲突时编译器会调用 key 的 operator == 函数进行进一步判断。参考
对 pair、tuple 定义哈希 1 2 3 4 5 6 7 8 struct hash_pair { template <class T1 , class T2 > size_t operator () (const pair<T1, T2> &p) const return hash <T1>()(p.fi) ^ hash <T2>()(p.se); } }; unordered_set<pair<int , int >, int , hash_pair> S; unordered_map<tuple<int , int , int >, int , hash_pair> M;
对结构体定义哈希 需要两个条件,一个是在结构体中重载等于号(区别于非哈希容器需要重载小于号,如上所述,当冲突时编译器需要根据重载的等于号判断),第二是写一个哈希函数。注意 hash<>() 的尖括号中的类型匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 struct fff { string x, y; int z; friend bool operator == (const fff &a, const fff &b) { return a.x == b.x || a.y == b.y || a.z == b.z; } }; struct hash_fff { size_t operator () (const fff &p) const return hash <string>()(p.x) ^ hash <string>()(p.y) ^ hash <int >()(p.z); } }; unordered_map<fff, int , hash_fff> mp;
对 vector 定义哈希 以下两个方法均可。注意 hash<>() 的尖括号中的类型匹配。
1 2 3 4 5 6 7 8 9 10 struct hash_vector { size_t operator () (const vector<int > &p) const size_t seed = 0 ; for (auto it : p) { seed ^= hash <int >()(it); } return seed; } }; unordered_map<vector<int >, int , hash_vector> mp;
1 2 3 4 5 6 7 8 9 10 11 12 namespace std { template <> struct hash <vector<int >> { size_t operator () (const vector<int > &p) const size_t seed = 0 ; for (int i : p) { seed ^= hash <int >()(i) + 0x9e3779b9 + (seed << 6 ) + (seed >> 2 ); } return seed; } }; } unordered_set<vector<int > > S;
程序标准化 使用 Lambda 函数
需要注意的是,虽然 function 定义时已经声明了返回值类型了,但是有的时候会出错(例如,声明返回 long long 但是返回 int ,原因没去了解),所以推荐在后面使用 -> 再行声明一遍。
1 2 3 4 5 6 7 8 function<void (int , int )> clac = [&](int x, int y) -> void { }; clac (1 , 2 );function<bool (int )> dfs = [&](int x) -> bool { return dfs (x + 1 ); }; dfs (1 );
不需要使用递归函数时,直接用 auto 替换 function 即可。
1 2 auto clac = [&](int x, int y) -> void {};
相较于 function 写法,需要额外引用一遍自身。
1 2 3 4 auto dfs = [&](auto self, int x) -> bool { return self (self, x + 1 ); }; dfs (dfs, 1 );
使用构造函数 可以将一些必要的声明和预处理放在构造函数,在编译时,无论放置在程序的哪个位置,都会先于主函数进行。下方是我将输入流控制声明的过程。
1 2 3 4 5 6 7 8 int __FAST_IO__ = []() { ios::sync_with_stdio (0 ), cin.tie (0 ); cout.tie (0 ); cout << fixed << setprecision (12 ); freopen ("out.txt" , "r" , stdin); freopen ("in.txt" , "w" , stdout); return 0 ; }();
/END/